Sequence to Sequence Learning with Neural Networks - 论文精读学习笔记
You are what you eat.
And I'm cooking what I eat! :)
目录
Sequence to Sequence Learning with Neural Networks - 论文精读学习笔记问题解决方法 -- 论文解读1解决方法关于模型的一些知识:处理序列目前的商用软件中实现情况(截至:2018.11)附加收获简记参考网页
提前说明:本系列博文主要是对参考博文的解读与重述(对重点信息进行标记、或者整段摘录加深自己的记忆和理解、融合多个博文的精髓、统合不同的代表性的案例),仅做学习记录笔记使用。与君共享,希望一同进步。
问题
传统的深度神经网络(Deep Neural Network, DNN)不能处理输入和输出都是变长序列的问题;
虽然DNN有着很强的能力,但只能将源序列和目标序列都编译为固定维度的向量。这是一个致命的缺陷,因为很多问题都无法提前预知被表示序列的长度,例如语音识别与机器翻译。
深度学习的基本思路:
大部分的深度神经网络仍然需要输入和输出的大小固定不变;
并将一层一层不同类型的网络层组合在一起;
通过巨量的数据、更有效的优化方法和训练技巧来达到目的。
这里的内容主要是说:文本的处理,但是同时也提到了关于图像的处理。意在表明,深度神经网络在处理变长数据的时候是没法直接处理的,需要有一个预处理的步骤:变长的数据 → 等长的数据。
举个例子,图像识别中的图像一般也不是固定大小的,输入前一般都需要进行预处理将图像规整到同一尺寸。
循环神经网络(RNN)
一种在空间结构上非常简单的模型。
相比传统的前馈神经网络(Feedforward Neural Network, FNN),RNN 的独特之处在于其隐藏层的一个环状结构,这个结构相当于能够缓存当前的输入,并用之参与下一次的计算,这样就隐式地将 时间信息 包含到模型中去了,在输入变长序列时,可以序列中的最小单元逐个输入。
RNN的优劣
空间结构上很简单;
(训练时)需要在时间维度上展开,所以可以认为它是一个在时间维度上的 DNN,于是 DNN 训练中会出现的 gradient vanish (梯度消失)也会出现,直观上可以将其理解为 "记忆的衰退"。(随着时间的拉长,一开始输入的数据逐渐起不到啥作用了)
换句话说, RNN 只能 "记住" 短期的信息。1997 年 "长短期记忆单元(Long Short-Term Memory, LSTM)" 被提出来解决这个问题,而本文提出的模型就是利用了 LSTM 的优点。
RNN的问题(RNN的结构 → 时间维度上出现记忆衰退 → 引出LSTM)
使用了两个不同的LSTM,一个用于输入序列,一个用于输出序列。因为这样能在小到几乎可以忽略的计算消耗下增加更多的模型参数;
作者发现深层LSTM的表现显著优于浅层LSTM,所以最终选用四层LSTM;
颠倒输入句子的单词顺序非常有用。举例来说,不是把句子a,b,c映射为句子α,β,γ,而是把c,b,a映射为α,β,γ。这样做使得a非常靠近α,b非常靠近β,以此SGD就很容易在输入和输出之间"建立通信",这种简单的数据转换大大提高了LSTM的性能。
解决方法 -- 论文解读1
作者提出将2个RNN组合起来:
→ 以更加灵活地处理变长输入序列和变长输出序列。
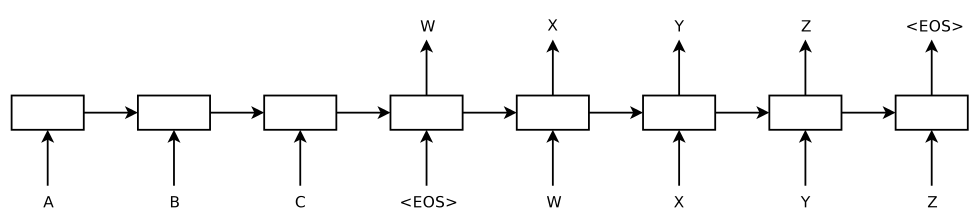
其模型结构如下,这是一个已经unroll的网络结构。疑惑
模型的左侧(到输入为
为止)是一个 RNN 在输入序列 "ABC " 上的展开,右侧是在输出序列 "wxyz " 上的展开,其中 是一个表示序列结束的特殊符号。End of Sequence 功能上:
第一个 RNN 用来将输入序列映射成一个固定长度的向量,这个 "固定长度的向量" 即是 RNN 中间隐藏层所缓存的对整个输入序列的 "记忆",我们可以说它表示了输入序列的语义;
然后用第二个 RNN ,来从这个向量中得到期望的输出序列。
此外:
除了这个特殊的模型结构之外,再就是用 LSTM 来保留 一定程度 的长期记忆信息;
并且作者表示复杂的网络结构(更多的参数)具有更强的表达能力,因此每个 RNN 用的都是 4 层的 LSTM, 参数两多达 380M, 也就是 38 亿。
每个RNN用的都是4层的LSTM是什么意思?
作者说将输入序列倒序后,效果得到了显著地改善,BLEU 从使用该方法之前的 25.9 上升到 30.6,然而自己也对其原因表示不太清楚,只作出了一些猜想(也就是说,并无明确的理论依据)。
“将输入序列倒序”:解释?
By reversing the words in the source sentence, the average distance between corresponding words in the source and target language is unchanged. However, the first few words in the source language are now very close to the first few words in the target language, so the problem's minimal time lag is greatly reduced.
自己的理解案例:
A B C → a b c (源语句没有倒序之前,A距离a比较远。)
C B A → a b c (源语句倒序之后,A距离a很近了。)
上面两种情况,源语言到目标语言的平均距离都没有变。但是倒序之后,单个源字符到目标字符的距离却更近了。
论文解读2的理解:
作者起初认为逆转源序列只会对句子的前半部分取得良好的表现,对后半部分的优化会较差。然而实际表现都很好。为什么有这样的奇效呢?其实可以这么理解,当我们将输入句子倒序后,输入句子与输出句子之间的平均距离其实并没有改变,而在倒序前,输入与输出之间的最小距离是很大的,并且每个词与其对应的翻译词的间隔是相同的,而倒序后,前面的词(与其翻译词)之间的间隔变小,后面的词(与其翻译词)间隔变大,但前面间隔小的词所带来的性能提升非常大,以至于能够使得后面的翻译效果不降反增。
“BLEU”:猜测应该是一个指标。
解决方法
解决问题的思路(论文解读2的描述):
先用一层LSTM读入源序列,逐步获得大量维度固定的表示向量,
然后用另一层LSTM从向量中提取出目标序列。
第二层LSTM本质上是一个语言模型。由于输入和输出之间存在相当大的时间延迟,所以使用LSTM对具有长期时间依赖性的数据进行训练是相当好的选择。
解决问题的思路(论文解读3的描述):
先用一层LSTM去读入源序列,逐步地获得大量维度固定的向量表示;
随后用另一层LSTM去从向量中提取出目标序列 。
第二层LSTM本质上是一个取决于源序列的周期性神经网络(Recurrent Neural Network, RNN)语言模型。考虑到相当大的时间滞后,LSTM能利用长时间范围内的相关性从数据中学习的能力让它成为此次应用的最佳选择。
LSTM的优点:
LSTM反过来读取输入语句的时候,可以引入更多的短期依赖,从而使优化更容易。
LSTM训练很长的句子也没什么问题;
LSTM的一个重要特质是它能够学会将不同长度的句子映射在一个维度固定的向量。(常规的翻译倾向于逐字逐句翻译,但LSTM倾向于理解句子的含义,因为同样的句子在不同的语境中的含义有所不同)。
LSTM虽然能够解决长期依赖关系的问题,但是,本文中表示,如果源语句被反转(目标语句没有反转)时,LSTM的表现更好。
关于模型的一些知识:处理序列
RNN是前馈神经网络对于序列的一种自然泛化。即,给定一个输入序列,RNN可以通过一个公式得到输出序列。
只要提前知道输入序列和输出序列长度相同,RNN就可以轻松地将序列映射到序列。
通用的序列学习方法最简单的策略是使用一个RNN将源序列映射到固定大小的向量,然后是用另一个RNN将该向量映射为目标序列。
问题:虽然它原则上是可行的,但由于向RNN提供了所有相关信息,产生了长期依赖性,因此RNN变得很难训练。
解决:不过,总所周知,LSTM可以学习具有长期时间依赖性的问题,因此LSTM在这种情况下可能会成功。
LSTM的目标:估计出条件概率
其中,
且,长度
LSTM-LM是一种基于长短期记忆网络(LSTM)的语言模型
LSTM:
首先获得最后一个隐藏状态给出的固定维度向量v。
然后用一个标准的LSTM-LM公式计算
在这个等式中,
分布用词汇表中所有单词的softmax表示。同时需要在每个句子的结尾用""来标识,这使得模型能够定义所有可能长度序列的分布。
结论:
基于LSTM的机器翻译的成功说明了它只要在拥有足够的训练数据的前提下,同样能够在解决其他问题上发挥出色;
逆转源序列后的性能提升程度感到惊讶。
找到一个问题具有最大数量的短期相关性是非常重要的,因这样可以简化问题的解决。
我们相信一个标准的RNN在逆转源序列后能够更加容易被训练。
模型训练时,以最大化条件概率为目标。
我们实验的核心是在许多句子对上训练一个大而深的LSTM。通过最大化一个对数概率来训练这个网络,其中的概率是在给定源句子
此处S是训练集,训练完成后,根据LSTM找出最可能的翻译作为结果
待学习/回顾内容:
“softmax表示”的含义?
条件概率的定义和使用案例
"最大化条件概率"为目标的含义是什么?有没有一个例子呢?
beam search方法是什么方法?
即在模型参数确定的情况下,对输入序列
目前的商用软件中实现情况(截至:2018.11)
sequence to sequence 模型被提出后,由于其灵活性,受到了广泛的关注,我个人是很喜欢这个模型中的想法的。然而现在流行的几个开源库对 sequence to sequence 模型的支持仍然不太理想,它们都要求在模型定义时就将输入序列的最大长度和输出序列的最大长度确定,对于长度不足的,则要用特殊符号进行填充,并在模型内部或外部做一些特殊处理。
比如用 Python 的深度学习框架 Keras 来实现一个弱化版的 sequence to sequence 模型,可以这样
附加收获简记
Theano及其分叉PyTensor,是一个Python库和优化的编译器,用来操纵和求值数学表达式特别是矩阵值表达式。在其中,计算使用NumPy风格的语法来表达并被编译,用来在CPU或者GPU架构上高效的运行。
机器学习开源框架:Theano、Caffe、Torch 和 SciKit-learn
1 RNN的缺点,LSTM的优点。在这个问题中,用了LSTM;
2 LSTM的一些特点,以及针对此做的一些工作;
3 一些之前学过但是忘记功能的概念,需要好好的回忆一下;
4 实验复现一下看看呢?这里好像没有用很多GPU啥的~,并不是大模型哦~
参考网页
博文免责声明
本条博文信息主要整合自网络,部分内容为自己的理解写出来的,如有断章截句导致不正确或因个人水平有限未能详尽正确描述的地方,敬请各位读者指正;
引用出处可能没有完全追溯到原始来源,如因此冒犯到原创作者,请联系本人更正/删除;
博文的发布主要用于自我学习,其次希望帮助到有共同疑惑的朋友。